第2回では、「数値」や「グラフ」を見る前に、データとモデルの正体を見抜く必要があることを扱った。実測とシミュレーションを並べて「概ね合っている」と述べるだけの検証会が、なぜ危険なのかも示した。主観が入り込むと、検証結果は会議参加者の解釈に左右されやすくなる。そして、製品を市場に投入した後に不具合として顕在化することもある。原因追跡の段階で「比較方法が主観的だった」と判明しても、その時点では手遅れである。
では、どうすればよいのか。ここで多くの現場は「入力項目を増やす」という方向に進みがちである。しかしそれは、現場の反発を招くだけで終わることが多い。Work①で目指すのは、入力を増やすことではない。差異が確認でき、結果が再現できる情報だけを、最小限で確実に残すことである。言い換えれば、データ収集を「作業」ではなく「設計」として扱うということである。
本稿では、測定とシミュレーションを例に、何を残せば比較が成立し、再現性が担保できるのかを、現場の視点で整理する。さらに、これらが個人の暗黙知に埋もれないようにするための「仕組み化の出発点」まで示す。
目次
1. 現実:入力を増やすほど、データは形骸化する
「データを残そう」「DXのために情報を整備しよう」と言われたとき、多くの現場担当者は身構える。理由は単純で、入力が増えると仕事が増えるからである。しかも、入力した情報が誰にも使われず、監査のためだけに存在するように受け取られると、抵抗はさらに強くなる。現場の感覚としては自然である。
だが、ここで見落とされがちな事実がある。入力が増えること自体が問題なのではない。問題は、何のために残すのかが曖昧なまま、入力だけが増えることである。目的が曖昧だと、項目は際限なく増える。項目が増えると、入力は粗くなる。入力が粗くなると、データの信頼性が下がる。信頼性が下がると、誰にも活用されない。これが「データが形骸化する」典型的な構図である。
現場が嫌うのは入力そのものではなく、使い道が見えないまま増えていく入力である。
手入力を前提にしない設計へ置き換えることが、定着の近道になる。
Work①では、この悪循環を断ち切る。その鍵は、残す情報を「全部」ではなく「最小」に絞り、その最小セットが必ず残るように工程に組み込むことである。
2. まず結論:測定とシミュレーションは「環境」を残さない限り比較できない
測定とシミュレーションの差は、数値の差として現れる。しかし、その原因は多くの場合、数値そのものではない。測定環境とシミュレーション環境の差である。
環境が違えば、結果が違うのは当然である。にもかかわらず、環境情報が残っていないと、「なぜ違うか」が追えない。
比較の対象は結果の数値だけではない。その数値を生んだ条件セットまで残して初めて比較が成立する。
ここでいう環境情報とは、単に「装置名」や「ツール名」を書くことではない。次の2つを満たす情報である。
- 差異が確認できる(何が違ったかが分かる)
- 再現できる(別の人が同じ条件でやり直せる)
この2つを満たす最小セットを、測定とシミュレーションそれぞれで設計する。これがWork①の実務である。
3. 測定環境を整理する:再現性のある測定データに必要な情報
測定環境という言葉は曖昧である。「測定器はこれ」「条件はこれ」といっても、後から見た人が再現できないことは多い。測定は、装置だけで決まらない。治具、配線、プローブの当て方、試料の状態、温度、校正、帯域、トリガなど、いくつもの要素が関係する。だから「測定環境」は、次の観点で分解して残すのが望ましい。
3.1 使用機器:装置名だけでは不十分である
最低限、装置名・型式に加えて、装置が持つ設定の骨格が分かるようにする。
- 装置名、型式
- 装置の設定プリセットの名称とデフォルト値
- 変更した設定の要点(標準から何を変えたか)
装置は同じでも、ファームウェアのバージョン違いや既定値の差で結果が変わることがある。ここを曖昧にすると、再現性が崩れる。
3.2 測定条件:サンプリング周期と帯域は「正体」を変える
測定条件で大きな影響を与えるのは、サンプリング周期と帯域である。波形が鋭い現象ほど、ここで結論が変わる。
- サンプリング周期、サンプリングレート
- 帯域制限の有無
- フィルタ、平均化、平滑化の有無
- トリガ条件(何を基準点にしたか)
「ピークが見えない」問題の多くは、帯域とサンプリングで説明できる。逆に、ここが不明だと、結果は比較不能になる。
3.3 治具・配線:寄生成分は「環境」そのものである
治具や配線の情報は、手間がかかるため省略されがちである。しかし実務では、ここが差分の主因になる。
- ケーブル長、配線の引き回し
- プローブ位置、GNDの取り方
- 治具の校正状態、治具のバージョン(改版があれば)
「同じ回路なのにリンギングが違う」「同じ製品なのにノイズが違う」といった事象は、治具・配線に起因して発生する。だから、せめて写真と要点メモで残すべきである。
3.4 試料情報:材料・寸法・ロット・前処理は「測定条件」に含める
試料の情報は、測定結果の解釈に直結する。電子デバイスでも車載機器でも、ロットや加工条件で特性が変動することは当たり前である。
- 材料、寸法、ロット
- 前処理(温度履歴、締結トルク、含水、焼きなまし等)
- 製造由来の暗黙知(残留応力、ひけ、鋳巣等が疑われる場合はその旨)
ここで重要なのは、完璧に書くことではない。「疑わしい要素がある」と気づける足跡を残すことである。
3.5 測定の様子:写真は「メタデータ」である
測定の様子を示す写真は、単なる記録ではない。差異を可視化し、再現の手がかりを与える有力なメタデータである。最低限、次の2枚は残したい。
- 全景(治具、配線、装置配置が分かる)
- 要点(プローブ位置、GND、対象部位が分かる接写)
文章で説明しにくい差分ほど、写真が有効である。
4. シミュレーション環境を整理する:再実行できる解析データに必要な情報
シミュレーションは「やり直せる」と思われがちだが、現実には必ずしもそうではない。モデルの元がどれか分からない、どの簡略化を入れたか分からない、物性がどこから来たか分からない、設定がどこに書かれているか分からない。こうなると、再実行はできない。できたとしても、異なる解析が実行される。
シミュレーションも、前提が固定されていなければ、再実行できても再現とは言えない。
だから、シミュレーション環境は次の観点で分解して残す。
4.1 モデル元:CADや回路図は「出典」として固定する
- CADデータ、回路、ネットリスト、部品モデルの出典
- どれを正とするか(基準データ)
- 更新履歴(誰が、いつ、何を変えたか)
モデル元が曖昧だと、結果は議論できない。
4.2 材料物性:物性はシミュレーションの中核である
材料物性は「代表値を入れた」で済ませると、後から必ず困る。最低限、次を残す。
- 物性テーブルの出典(測定、文献、メーカ、社内DBなど)
- 温度依存、周波数依存、応力依存の扱い(無視したか、近似したか)
- 採用根拠(代表値、測定値、推定値)
- 適用範囲(どの温度・周波数条件に有効か)
- 更新履歴(いつ変えたか、なぜ変えたか)
物性が変われば結果は変わる。物性の出典が追えない解析は、再現性がない。
4.3 モデルリダクション:簡略化するほど、結果の意味が変わる
- 省略箇所(何を捨てたか)
- 簡略化方針(なぜ捨てたか)
- メッシュ粒度(どれくらい荒くしたか)
- 近似モデル(等価回路、簡易熱モデル等)の選択理由
「計算負荷が高く、そのままでは実行が難しいため簡略化した」という判断自体は、現場では珍しくない。だからこそ、簡略化の履歴を残さないと、結果の正体が分からなくなる。
4.4 設定条件と数値条件:境界条件と収束条件は結果を作る
- 境界条件、励振条件、初期条件
- 評価区間(どこを比較対象にするか)
- 収束条件、時間刻み、精度オプション
- ソルバ設定(既定値から変えた点)
ここが曖昧だと、「同じモデルを回したのに違う」という事態が起きる。
4.5 ツール情報:バージョンは必須メタデータである
- ツール名、バージョン
- 主要設定パラメータ
- 可能なら設定ファイルやプロジェクトファイルそのもの
「スクリーンショットだけ共有」という形は避けたい。なぜなら、画像だけでは設定値や差分を機械的に利用できないからである。機械的に処理できるデータで、かつ再実行できる単位で残すべきである。
5. 属人化を防ぐWork①:入力を増やさずに使えるデータを残す3点セット
ここまで読むと「結局、残すものが多い」と感じるかもしれない。だがWork①の狙いは、残す項目を増やすことではない。残すべき最小セットが、自然に残る仕組みを作ることだ。実務では、次の3点セットが有効である。
ここで固定したいのは項目数ではなく、残す場所と残し方である。
5.1 必須メタデータを固定する(測定用・解析用の最小テンプレ)
測定とシミュレーションで、それぞれ「最小セット」をテンプレ化し、毎回同じ場所に書く。ここで重要なのは、テンプレが短いことである。長いテンプレは定着しない。例えば、次のように5~8行に絞る。
- 測定:装置、条件(周期・帯域)、治具・配線、試料(材料・寸法・ロット)、写真リンク、実施者・日付・レビュー者
- 解析:モデル元(CADデータ)、モデルデータ・リダクション手法、材料物性、解析・収束条件、ツールバージョン、実施者・日付・レビュー者
テンプレは「報告書の冒頭」か「図の脚注」に埋め込んで、人が必ず見る場所に置くのが望ましい。
以下の挿絵は、テンプレをベースにして検証している様子を示したものである。項目ごとに整理・確認することで、データ差異が発生した要因、または類似性が高かった要因を整理し、可視化できるようになる。

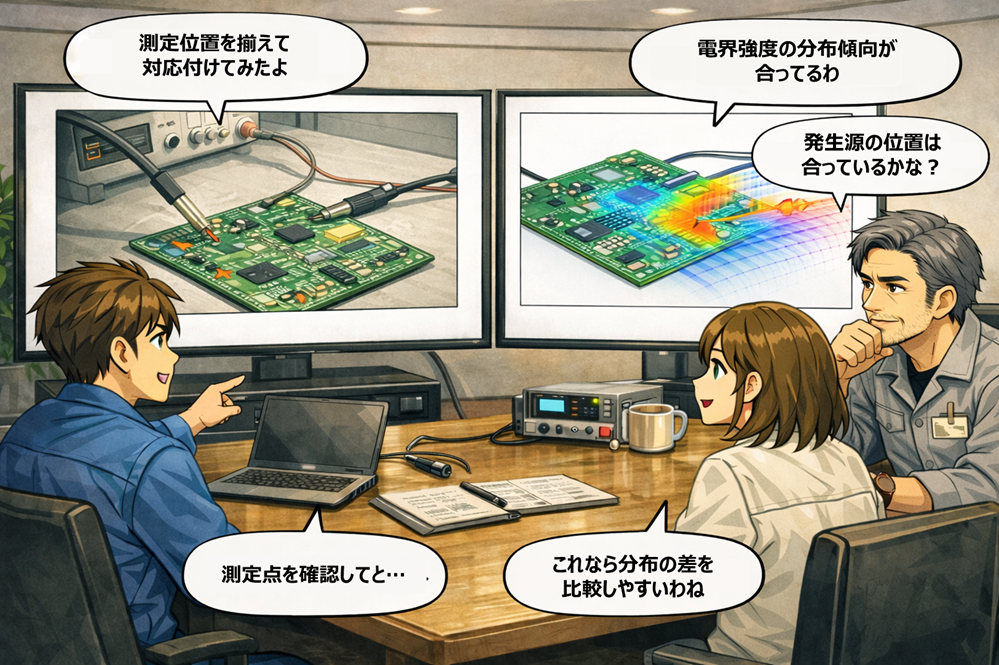
担当者情報は「再現性メタデータ」である
測定やシミュレーションの履歴に、担当者名(実施者)を残すことは必須である。可能なら、実施者に加えてレビュー者(承認者)も残すべきだ。これは責任追跡のためではない。再現性のためである。現場の作業は手順書どおりに見えても、治具の当て方、測定の勘所、解析の収束のさせ方など、暗黙の差が結果に反映される。最後にその差異を補足できるのは「誰が実施したか」という情報であり、疑問点を確認するための最終手段となる。
昨今、製造業の開発現場では、実機テストやシミュレーション作業を委託先(協力会社や派遣メンバー)に任せることが増えている。この業務構造では、Work①が定まっていないと「結果だけ」が納品され、委託先がどのようにデータを採取し、どのようにモデルを作り、どのように設定したかが分からない。後から確認しようとしても、本人が別案件に移っていたり、作業内容が記憶に依存していたりして、結局追跡できない。ここでも、手戻りが発生しやすい。だからこそ、最小テンプレの中に(実施者・日付・レビュー者)を組み込み、委託先の場合は会社名も併記して、「個別に確認しなくても追跡できる」状態を先に作る必要がある。
委託先を含む体制では、この追跡情報がないだけで確認コストが一気に跳ね上がる。
5.2 自動で取れるものは自動で取る
現場が負担と感じるのは、手入力である。逆に、ツールが自動的に記録するのであれば抵抗は小さい。「人が手作業で補わなくても記録が残る」状態を作ることが、属人化を防ぐ最短ルートである。
(*1) Git:分散型バージョン管理システム(変更履歴を管理する仕組み)
(*2) PLM:Product Lifecycle Management、製品ライフサイクル管理
5.3 成果物に埋め込む(別管理にしない)
「仕様書は別ファイル」「ログは別フォルダ」「写真はどこかの個人フォルダ」になると、情報は必ず分散する。成果物の中に埋め込むのがよい。
成果物の外に置かれた情報は、時間がたつほど参照されにくくなる。
- 報告書の冒頭に最小テンプレ
- 図の脚注に測定条件と解析条件
- 解析プロジェクトにREADMEを置く
- 測定写真を成果物フォルダに同梱する
別管理は、整理されているように見えても運用で破綻しやすい。Work①では、成果物に埋め込む置き方を優先する。
6. ミニ事例:測定データとシミュレーション結果を比較できなかった理由
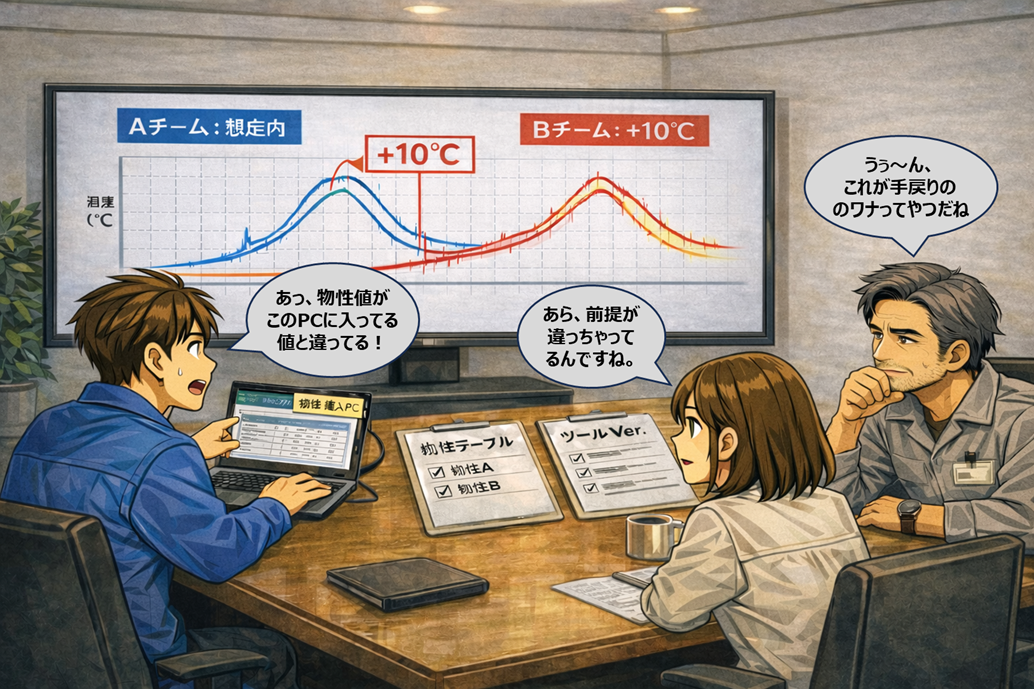
ある案件で、検証担当が「シミュレーションでは温度ピークは想定内」と報告し、開発判断が進みかけた。ところが別チームが同じモデルを回すと、温度ピークが10℃以上高い。原因を追うと、ツールのマイナーバージョン差で既定ソルバ設定が変わっていた。さらに材料物性テーブルの一部が個人PCにだけ残っており、共有フォルダの解析プロジェクトには反映されていなかった。
個々の結果自体が直ちに誤っていたわけではない。問題は、結果がどの前提(正体)で成立しているかが固定・共有されていなかったことだ。そして気づかぬうちに、手戻りを招いていたのである。
この事例は特別ではない。測定でも同じことが起きる。装置は同じでも帯域が違う。治具は同じでも校正状態が違う。サンプリング周期が違う。試料の前処理が違う。これらの差は、結果の正体を変える。しかし差分が残っていないと、「なぜ違うか」に到達できない。到達できないから、再実験や再解析が発生する。これが手戻りである。
比較不能だったのではない。比較の前提が途切れていただけである。
7. まとめ:差異確認と再現に必要な情報だけを残す
Work①の結論は単純である。入力を増やすのではない。差異が確認でき、再現できるための情報だけを、最小セットで残すのである。測定なら、装置・条件・治具・配線・試料・写真である。シミュレーションなら、モデル元・材料物性・リダクション・条件・収束・ツールバージョンである。そして、それらは別管理にせず、成果物に埋め込む。
要点は、「残す量」を増やすことではなく、「差異確認と再現に必要な情報だけが残る状態」を作ることである。
本当は、測定とシミュレーションそれぞれに「仕様書」が必要である。だが最初から立派な仕様書を作ろうとすると頓挫する。まずは、今回示した最小セットを「毎回残る形」に埋め込み、次回以降で部門標準としての仕様書へ育てていく。
あなたの職場で、測定結果やシミュレーション結果は「再現できる形」で残っているだろうか。それとも、今日も誰かの頭の中にだけ残っているだろうか。



