今回もデータの見方について解説していく。
第1回では、データシートは「条件付きの契約書」であり、数値だけを見ても比較は成立しないことを解説した。第2回では数値を評価する前段として前提を確認する。そもそもその数値(あるいはそのグラフ)がどの前提で成立しているかである。
同じ「95%」「10ms」「温度上昇△8℃」でも、それが生データなのか、加工データなのか、推定値なのか、集計値なのかによって、意味と限界は変わる。そして昨今この問題は「測定データ」だけでなく、シミュレーション結果でも同様に表面化している。
試作レス(物理試作を減らし、解析・シミュレーション中心で進める開発)が進むほどシミュレーションは意思決定の中核を担う。しかし組織でデータの「正体」つまりそのデータの前提・作成経緯の確認が標準化されていないと、後から前提の不一致が判明し、手戻りが発生する。
ここで第1回と同様に、開発担当、検証担当、品質担当の3者でよくある場面を再現する。

開発担当:「シミュレーションでは温度ピークは許容範囲内です。これで設計を前に進められます。」
検証担当:「実測とシミュレーションの条件も概ね揃っていますね。」
品質担当:「その結果は再現できますか? モデルのバージョン、材料物性、境界条件、解析設定、ツールのバージョンは記録されていますか?」
開発担当:「結果は良好で、グラフも見やすくまとめています。」
品質担当:「綺麗なグラフほど注意が必要です。前提が不明確だと、比較も再現もできません。」
検証担当:「同じモデルでも実行環境が違うと、結果に差が出ることがあります。まず前提を固定しましょう。」
Read②で身につけたいのは結果を見る前に「正体」を確認する質問ができることである。ここでいう正体とは二つある。
- データの正体(Raw・Processed・Metric、粒度、欠損、誤差)
- モデルの正体(モデルのバージョン、物性値、境界条件、解析条件、ツール・ソルバのバージョン、設定)
さらに指標データではテストベンチ(評価ベンチ)の仕様が前提を規定する。試作レス時代は、この三点セットが揃わない限り、結果は組織の資産になりにくい。
では具体的に何に注目したらいいのかについて見ていこう。。
データのチェック項目①:設計・製造・シミュレーションで意味が変わる3種類のデータ
データを受け取ったらまず次の3つに仕分けする。これだけでも手戻りは減らしやすい。重要なのは同じ「生データ」という言葉でも、部署や工程によって指しているものが違うという事実である。定義のずれが残存したままでは、議論は用語だけが共有された「つながっているだけ」の状態から進むことができない。
1) 生データ(Raw)とは:設計・製造で「一次データ」の意味が違う
生データは一般に「測定器やシステムが出力した一次データ」と説明されるが、設計・製造の現場ではもう少し広い意味で扱われる。設計ではCADデータや物性値、製造では実寸法・試験結果・工程ログが、しばしば“生”として扱われる。
設計現場の生データはしばしばCADデータ(形状情報)や材料・部品の物性値データである。ただし物性値は、ある条件下のみで測定された値であることが多く、製品が置かれる環境の全て(温度域、周波数域、応力状態、経時変化)を含んでいるとは限らない。つまり「一次情報ではあっても、適用範囲が記録されていない場合がある」という注意点がある。
製造現場の生データは試作品や量産品の実寸法、強度・特性試験データ、工程内検査のログなどである。例えば実寸法は、CAD寸法の公差内に入っていてもばらつきがある。ばらつきは不良ではなく「現実」であり、この現実を無視した設計・評価は後工程で成立しにくくなる。
さらに重要なのは、製造のデータにはしばしば加工条件に起因する「見えにくい前提」が内在することである。例えば、板金加工なら曲げやプレスの条件によって残留応力が入り、歪みや反りとして後から影響してくる。鋳造なら、冷却条件や肉厚によってひけや鋳巣が発生し、強度低下や寿命のばらつきとして現れる。
つまり、製造現場の生データは「測った値」ではあるが、同時に「製造条件が反映された値」でもある。この「条件の影響」が言語化されないと、設計側はデータを都合よく解釈し、製造側は「設計者は現場を知らない」と感じる。ここでも手戻りが発生する。
このように、部署ごとに「持っている生データ」が違い、さらに見ている粒度も違う。Read②で最初にやるべきは、データそのものの議論ではなく、その部署が「生データ」と呼んでいる対象の定義合わせである。
2) 加工データ(Processed)とは:軽量化・近似・取り込みで別物になる
加工データは、離散化、フィルタや補正処理、単位換算、外れ値除去といった処理が入ったデータである。シミュレーションでは、この「加工」がさらに重い意味を持つ。なぜなら、シミュレーションでは多くの場合、現実をそのまま扱えないからだ。
- CAD通りにモデル化すると計算負荷が高く、実行時間が現実的でない場合がある。そのため、簡略化や形状の省略が入る。
- メッシュ化(離散化)を行うことで、境界が階段状になり(離散化誤差が生じ)、メッシュサイズが粗いほど計算誤差が増えやすくなる。
- 解析プロジェクトにインポートする部品モデル(例:電子デバイス)の素性が不明確なことがある。メーカーがWebで配布しているモデル、開発現場が独自に作成したモデル、さらにそれらから派生したモデルが混在し、「どのバージョンの、何を近似したモデルか」が追えないまま使われる。
ここで言う加工とは単にデータを整形したという意味ではない。軽量化・近似・モデル選択によって、データの前提が変わっているという意味である。加工の履歴が残っていない結果は、比較も再現もできない。
3) 指標データ(Metric)とは:テストベンチ仕様の上に成り立つ判断用の数値
指標データは集計・平均・合成・推定を経て「1つの数字」になったものである。言い換えれば、判断のために情報を圧縮し、ばらつきや時間変化の一部を捨てた数値でもある。現場で扱う指標の多くは、設計要件、実機テスト要件、国際試験規格などを模擬した「判断のための基準(クライテリア)」である。
例えば、車載機器の電子デバイスでは次のような指標が典型である。
- モータ制御回路のスイッチングに伴うリンギング電圧がMOSFETの定格を超えていないか
- スイッチング損失による発熱が許容範囲内か
- 放熱(冷却)設計が目標要件をクリアできているか(温度上昇、熱抵抗、限界温度)
ここで見落とされやすいのが指標データを作るためのテストベンチ(評価系)の仕様差である。同じ「リンギング電圧」でも、テストベンチが違えば同一指標として比較できない場合がある。例えば次のような差異が、数値の解釈を変える。
- 配線・寄生成分:配線長、レイアウト、プローブの取り付け位置で寄生インダクタンス・寄生容量が変わる
- 測定器・帯域:帯域制限、サンプリング周波数、フィルタ設定により、ピークが過小評価・過大評価される
- 負荷・電源条件:電源インピーダンス、負荷条件(L負荷、抵抗負荷、モータ等)、ケーブルの有無
- 駆動条件:ゲート抵抗、ドライバ、デッドタイム、立上り・立下りの定義
- 初期条件・温度:温度・予熱条件、初期電流、SoC(充電状態)・SoH(劣化度合い)
シミュレーションでも同様である。テストベンチに相当するのは、回路構成、境界条件、励振条件、モデルの接続方法である。つまり、指標データは「結果」ではなく、テストベンチ仕様という前提の上に成立する。
テストベンチが揃っていない指標比較は、条件が揃っていないデータシート比較と同じで、結論を早く出せる一方で手戻り発生の要因となる。
データのチェック項目②:粒度・欠損・誤差を揃えて「主観による検証」をやめる
粒度(どの単位で記録し、どの単位で集計しているか)が揃っていないと、同じ指標名でも別物になる。「平均」と書いてあっても、母集団、区間、重み付け(何をどう割ったか)が不明なら比較不能である。電子デバイスでも車載でも、ピークを問題にするのか、時間平均を重視するのかで結論は変わる。粒度が揃わないまま共有が進むと、議論は「数値の優劣」に寄るが、後工程で破綻しやすい。
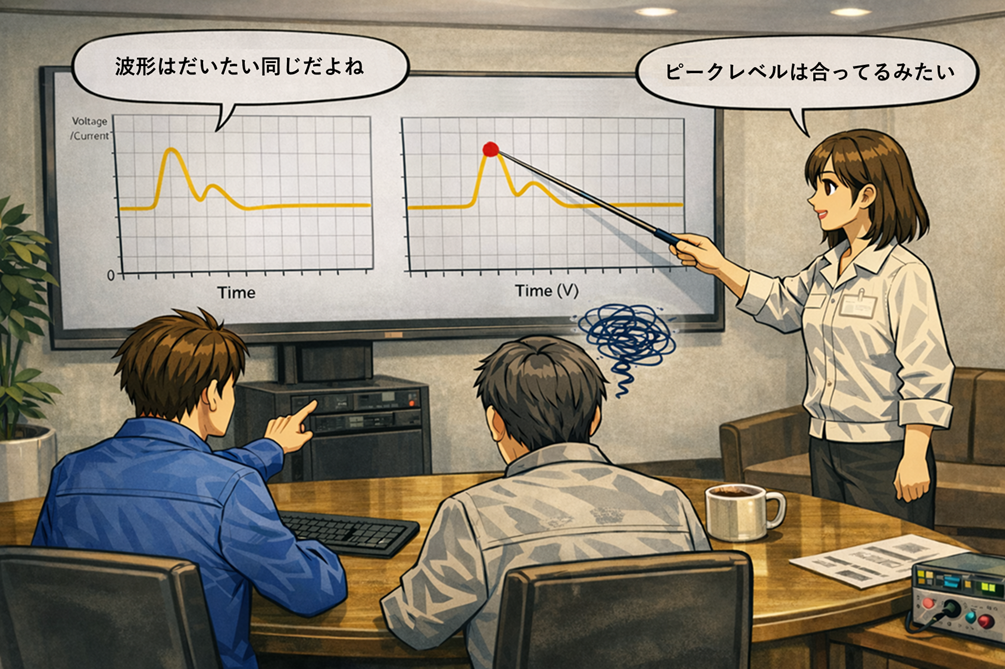
ここで、試作レス開発の現場で頻発する「検証会でよくある場面」を挙げる。実測のグラフを左、シミュレーションのグラフを右に置いて、「概ね特性が合っている」と確認して終える場面である。一見すると効率的だが、注意が必要である。理由は二つある。
- 別々のグラフを見比べると、粒度の差が見えにくい。サンプリング周期、時間軸の基準点、平滑化の有無、表示スケールが少し違うだけで、人間の目は「似ている」と判断しやすい。
- 「似ている」「だいたい一致している」は評価語であり主観である。主観的評価に依存した時点で、結論は参加者の解釈差に左右され、検証の再現性が残りにくい。
こうした見落としが、製品を市場に出してから不具合として顕在化することもある。原因追跡の段階で「実測とシミュレーションの比較方法が主観的だった」と分かっても、その時点では手戻りコストが跳ね上がる。
したがってRead②として最低限やるべきことは二つである。
1) 2つの波形は1つのグラフに重ねる
重ねる前に、時間軸の合わせ方(基準点)、スケール、フィルタ、平滑化などの前処理条件を揃える必要がある。条件を固定して重ねた瞬間に、時間ずれ、振幅差、立上り・立下りの差、ピーク付近の差がはっきりと見える。
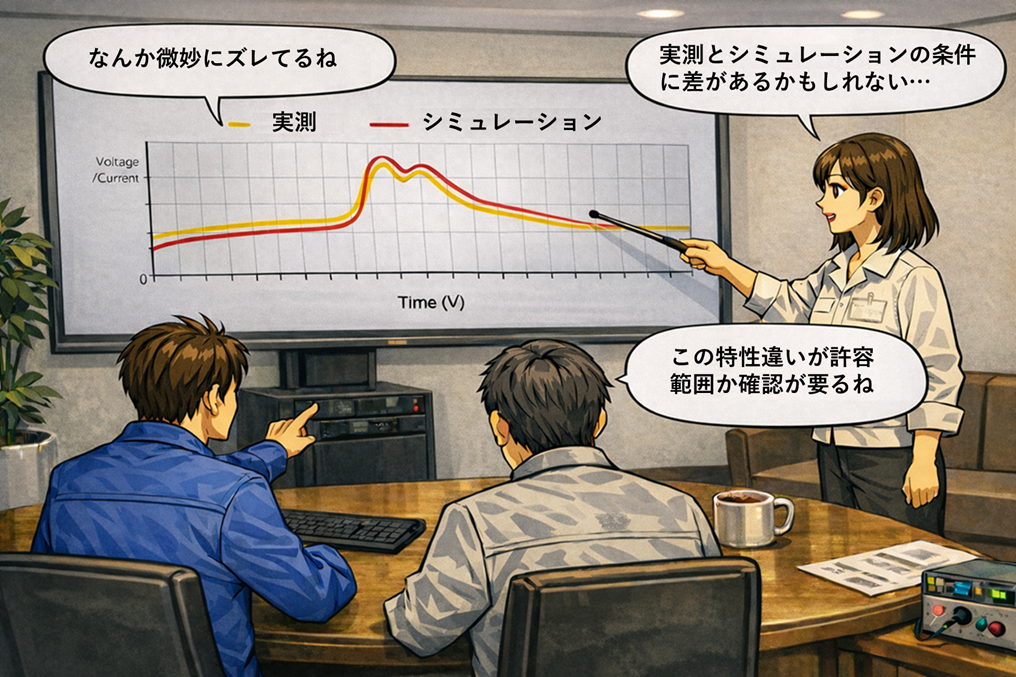
2) 「似ている」を数値化する(時間ずれ・振幅差・形状差・区間誤差)
類似度を数値化しない限り、検証は合意形成に留まり、再現性が残りにくい。難しい話ではない。最小セットとして、例えば以下のような指標で十分である。
- 時間ずれ(ピーク時刻差、立上り10~90%時刻差など)
- 振幅差(ピーク差、平均差、RMS誤差など)
- 形状差(相関係数、正規化RMSEなど)
- 重要区間での誤差(スイッチング近傍、ピーク近傍などの区間指定)
ここで重要なのは、どの指標を選ぶかよりも、指標を決める前提(粒度・欠損・誤差)を揃えることである。実測に欠損があれば、欠損区間を除外するのか補間するのかで誤差指標は変わる。サンプリング周期が違えば、リサンプリングや時間合わせのルールが必要になる。測定系の帯域制限が入っていれば、シミュレーション側にも同等のフィルタを適用しない限り、公平な比較にならない。
「重ねて眺める」と「数値化する」は、どちらも検証コストに見える。だが、これを省略して「だいたい一致」と言った瞬間から、後工程で手戻りが発生しやすくなる。Read②がやるべきことは検証から主観的判断を排し、比較可能な状態に戻すことである。
データのチェック項目③:試作レスでは「モデルの正体」が再現性を決める
ここが第2回の要点である。試作レスでは「結果の前提」を決めるのはデータだけではない。モデルそのものの正体(前提)である。ここが曖昧なまま共有されると、再現性は崩れやすい。
モデルのバージョン・派生・更新履歴をベースライン化する
- モデルのバージョン:どのバージョンのモデルか(更新履歴、差分、派生)
同じモデル名でも、派生や差分の所在が追えないまま使われると、比較も再現もできない。まず「どの版を正とするか」を固定し、更新履歴と差分の場所を紐づける必要がある。
材料物性・境界条件・解析条件をセットで記録する
- 材料物性値:出典、温度依存、採用根拠(代表値か、測定値か)
- 境界条件:入力波形、拘束条件、熱・機械・電気の結合条件
- 解析条件:メッシュ、時間刻み、収束条件、近似モデルの選択
これらは結果を直接動かす。記録が薄いまま共有されると、会議では「結果のスクリーンショット」だけが残り、再現も監査もできない状態が続く。
ツール・ソルバのバージョン差と既定値(暗黙の前提)に注意する
- ツール・ソルバのバージョン:バージョン差、既定値の違い、オプション設定
同じ入力・同じモデルのつもりでも、ツールの版や既定値の差(暗黙の前提)で結果がずれることがある。個人が頑張れば管理できる話ではない。だからこそ「データリテラシーは個人の素養ではなく、組織能力そのものなのである」という言葉が、現場で実感される。
前提の固定ができないまま共有だけ進めても、連携は単に「接続されているだけ」で終わる。
ミニ事例:同じモデルでも温度ピークが10℃以上ずれた原因(バージョン差・物性値の未共有)
ある案件で、検証担当が「モデルでは温度ピークは想定内」と報告し、開発判断が進みかけた。ところが別チームが同じモデルで解析すると、温度ピークが10℃以上高い。原因を追うと、ツールのマイナーバージョン差により既定のソルバ設定が変わっていた。さらに物性値テーブルの一部が個人PCにだけ残っており、共有フォルダのモデルには反映されていなかった。
結果は間違っていなかった。問題は、結果がどの前提で成立しているかが固定・共有されていなかったことだ。このままでは、気づかないうちに手戻りが発生しうる。
実務テンプレート:結果の「正体」を7行で
第2回の実務テンプレはこれである。データに5行、モデルに2行を足す。難しい分析は不要で、まずは書ける範囲でよい。
- 種類:生データ・加工データ・指標(何の数字か)
- 粒度:時間・個体・ロット等(平均なら「何の平均」か)
- 欠損・外れ値:割合と扱い(除外・補間・定義)
- 誤差・補正:測定精度、治具・校正、ログ周期(分解能)
- 作成履歴:作成者、作成日、前処理、ツール・バージョン
- モデルのバージョン:モデル名、バージョン、更新履歴(差分の所在)
- 評価ベンチ前提:テストベンチ仕様(実機)・解析ベンチ仕様(シミュレーション)の要点(配線・帯域・負荷・駆動・初期条件)
この7行が書けない結果は、比較と再現に弱い。逆に言えば、この7行が揃えば、結果は組織の資産になる。Read②の価値は分析を高度化することではない。手戻りが起きない状態を、先に作ることである。
数値やグラフは、判断を強く誘導する。だからこそ、前提が曖昧な数値は意思決定を損なう。第2回は、結果を見る前に、データとモデルの作成経緯、そしてテストベンチ前提を問う習慣を作る回である。
次回はWork①として、現場のデータ収集を「作業」ではなく「設計」として捉える。入力を増やさずに、使えるデータを増やす。あなたの職場で共有されている「指標」やシミュレーション結果は、この7行で「正体」を書けるだろうか。



